训练数据超20亿 云从科技视觉大模型刷新四项世界纪录
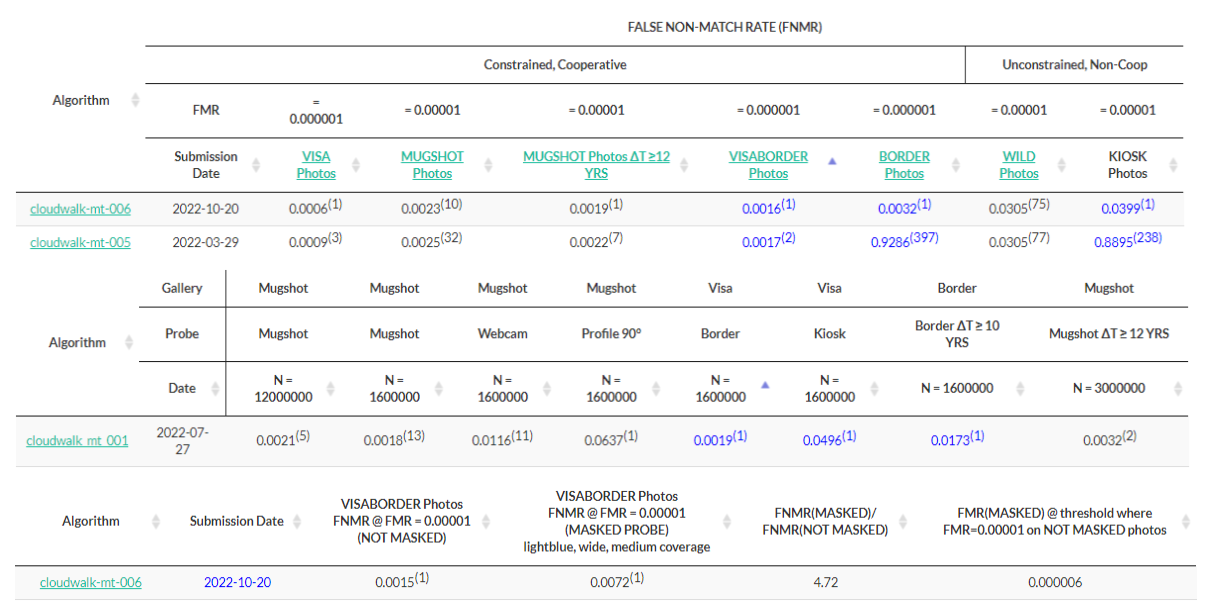
近日,云从科技在视觉大模型上取得重要进展,行人基础大模型在PA-100K、RAP V2、PETA、HICO-DET四个数据集上从阿里巴巴、日立等多家知名高校、企业与研究机构脱颖而出,刷新了世界纪录。
其中最高在PA100K上的Fine-tuning准确率达到92.89%,比SOTA高出5.2个点,四个数据集所涉及的范围覆盖人体全局属性(性别、年龄),局部属性(穿戴风格、配饰),携带属性(手机、刀棍、手提包等)、人-物交互HOI(抽烟,持刀棍,手机拍屏幕)等。
表1:云从科技在PA-100K、RAP V2、PETA行人属性数据集上的表现
作为“六感”之首的视觉,占据了人类吸收外部信息的70%以上。对于人工智能也一样,行人基础大模型让人工智能如何识别关于人的一切信息,准确率的提高具有非常高的实用价值,本次突破意味着该技术首次达到大规模商用水平,也意味着计算机视觉已经迈入「大模型时代」。
多模态结合自监督学习 打造全球领先核心技术
以人为中心的感知任务,一直是人工智能领域研究的热点,大模型具有强大的表征能力,并且在多种数据模态(如语言、音频、图像、视频、视觉语言)上得到验证。行人基础大模型已经发展成为视觉大模型基础,云从科技结合实际业务落地需求,研发以人为中心的预训练大模型,专注于以人为中心的各类下游任务,实践和贯彻“人机协同”理念。
表2:云从科技在HICO-DET人-物交互数据集上的表现
云从行人基础大模型,使用了超过20亿的数据,包括大量无标签数据集以及图文多模态数据集,数据集的丰富多样使得模型能够提取到非常稳健的特征,轻松应用于多种行人任务。
基于自监督学习范式,云从科技充分结合了对比学习和掩码学习的优点,使得模型包含丰富的语义信息,同时具有丰富的纹理细节提取能力。为了让模型学习拥有更加丰富的行人语义信息,结合多模态继续使用弱监督训练范式,进一步提升模型的效果。
在实际应用场景中,大模型与针对单一任务的专用模型相比,表现出很强的泛化性,可以大大节约对真实数据的需求,甚至不需要额外收集真实数据,极大节省了在下游任务上的迁移成本,可快速将大模型能力迁移到新的应用场景之中,并且可广泛应用于能源、交通、制造、金融等行业领域,并为这些行业打造专属的行业大模型,深度赋能。
基于基础预训练模型 大幅降低研发成本
传统的行人检测和分析存在诸多难点,包括缺乏对场景的理解,只能检测出所有目标;其次行人的某些特征非常细微,需要模型具有细粒度的识别能力,各种大姿态和环境干扰容易造成影响;最后,对行人的检测分析需求多变,层出不穷,大部分需要定制化开发。如何能够降低开发成本,在技术产业化的过程中非常关键。
基于从容大模型平台,开发者可以大幅降低对数据的依赖和提升训练效率,仅需要1%的数据量即可达到与原场景定制化开发模型相接近的效果,适合获取真实样本代价非常高的特殊行业。
目前,该技术已广泛应用于矿山、建筑工地以及特殊场所的安全布控,监控作业人员穿戴合规,姿态行为等异常和违规行为。
此前,云从科技跨镜追踪技术于2018-2020连续三年三次打破世界纪录,行人基础大模型的突破,表明云从从容大模型已经整合西部算力中心、联合研发中心、行业数据等资源,打造出了更优秀的人工智能视觉大模型,为实现人机协同操作系统和行业专用大模型在行业智能化升级领域的大规模实践打下了坚实的基础。
您可能感兴趣
-
-
 2025-04-01
2025-04-01近日,云从科技与重庆大学大数据与软件学院联合研发的编程智能体——CoSEFA(Code SEcurity and Fix Agent)被软件工程领域顶尖会议ACM SIGSOFT软件工程基础国际会议(FSE 2025)正式录用。
-
 2023-06-27
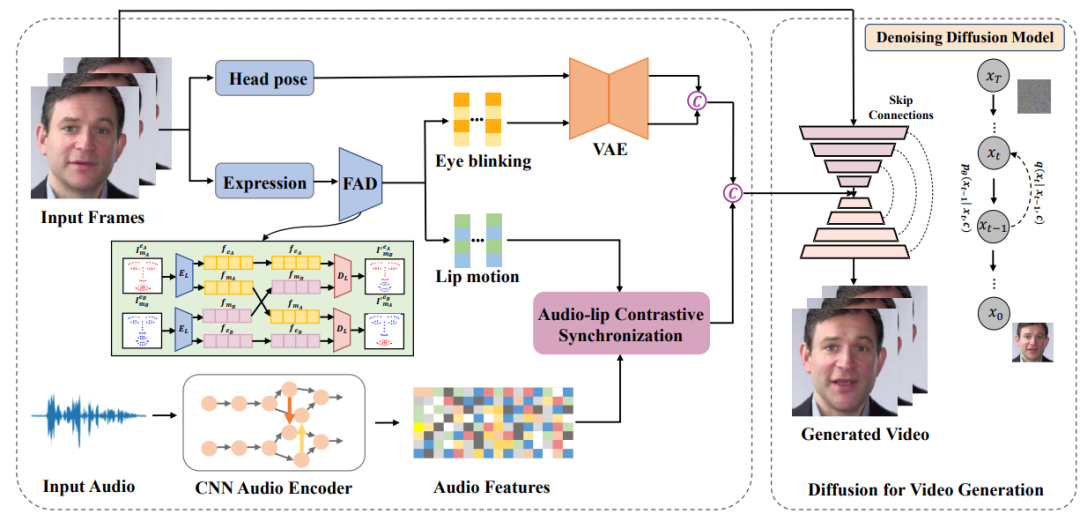
2023-06-27云从科技与上海交通大学联合研究团队的《基于扩散模型的音频驱动说话人生成》成功入选会议论文,并于大会进行现场宣讲,获得多方高度关注。







